Lightweight Threading Library and OpenMP Runtime System
- Note that these are done in collaboration with Argonne National Laboratory. The following mainly explains but is not limited to what we did by ourselves.
Parallel computation is essential to efficiently run a program on modern machines. One parallelism in hardware is core-level parallelism; one processor has multiple cores each of which has the full computing capability. Multithreading is a technique to run a single program on many cores by splitting computation as “threads” (or sometimes called “tasks”) and concurrently running them on multiple cores. However, it is challenging to exploit an increasing number of cores especially when parallel algorithms are irregular. Finer-grained parallelism is a keyword to keep all cores busy with meaningful computation. Traditional threading libraries (e.g., Pthreads) are not suitable for fine-grained parallelism because of their heavyweight nature.
Lightweight Threading Library
We are developing an extremely lightweight threading library and its wrapper layers, which can address the problem above. Programmers extract parallelism from the program and create numerous threads each of which denote concurrent computations. Our runtime system can efficiently execute them with tiny parallelization overheads to achieve high scalability.
We are exploring extremely lightweight threading techniques. Many people vaguely thought threads having more “threading capabilities” are heavier than threads having less capabilities; that is a typical black-and-white trade-off. However, unveiled was what threading features exist in this context and how much they cost. Our solid and deep performance analysis identifies such threading features (e.g., suspendability and stack size specification) and their associated costs. This study allows users to utilize a specific thread type employing threading features and performance exactly needed by users, which succeeds in ultimately reducing threading overheads. The figure below shows different techniques which have different set of threading features show different performance characteristics.
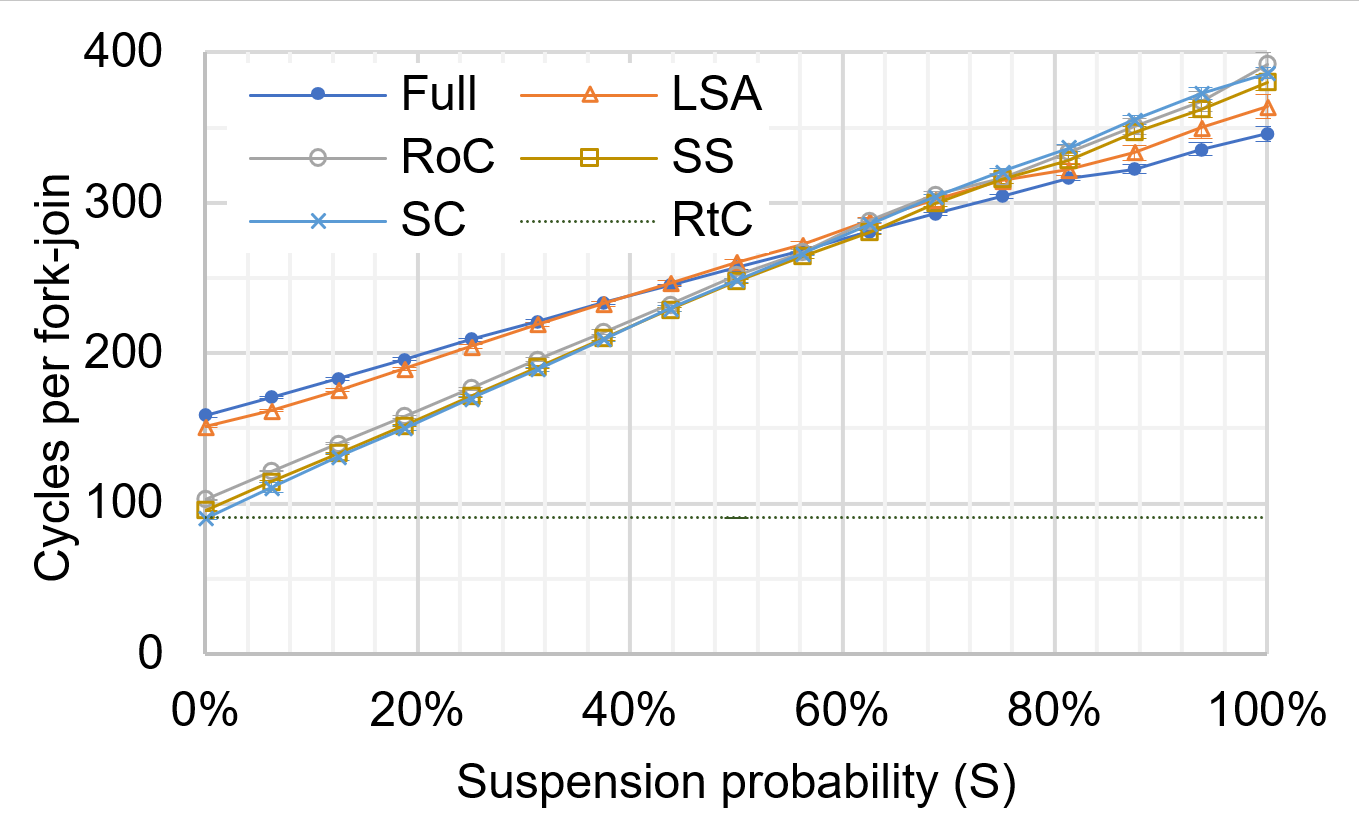
This figure presents performance (Y axis) of lightweight threading techniques (Full, LSA, … RtC). It shows that threading techniques achieve different performance associated with suspension probability (X axis), while each threading technique has different threading capabilities.
OpenMP Runtime System
Unfortunately, these lightweight threading techniques are too low level in practice. Most modern high-performance computing applications running on supercomputers use “OpenMP” for multithreading; asking application developers to use our own threading library is not practical. Hence, we are also developing fully compatible OpenMP runtime system over the lightweight threading library we developed. This OpenMP library “mostly” works with programs compiled with widely used production compilers and their runtime systems such as GCC, Clang and Intel OpenMP Compilers, so users can enjoy lightweight threads just by changing “LD_LIBRARY_PATH” and replacing the runtime library before execution. The following chart shows that BOLT (the OpenMP runtime system based on the lightweight threading library) can efficiently schedule work with smaller latency than Intel OpenMP. However, there are several challenges to use such a lightweight threading library in the OpenMP runtime system. We are currently investigating on how we can efficiently utilize lightweight threads in OpenMP in terms of the specification (OpenMP is an international specification that has 20-year history) and the real usage in real workloads.
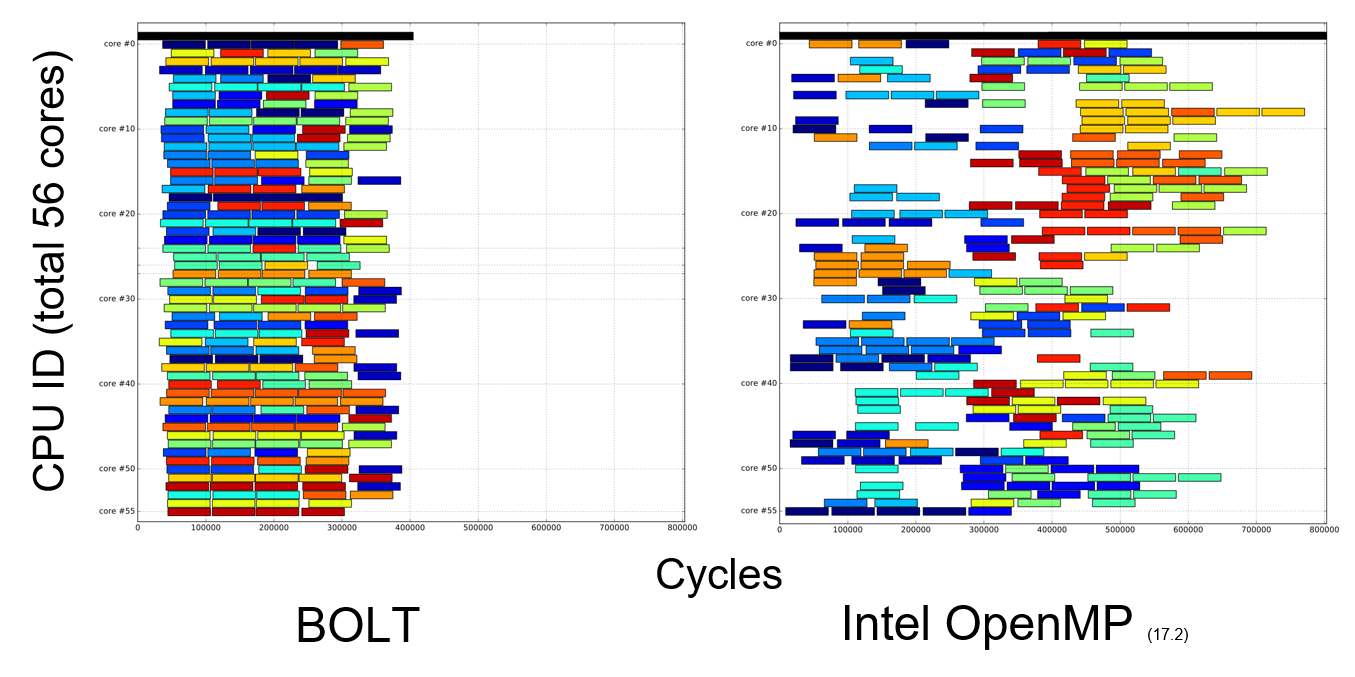
This figure shows job scheduling on BOLT, which we are developing, and Intel OpenMP. Each rectangle shows individual work. Compared to Intel OpenMP, which adopts traditional threading libraries, BOLT has smaller scheduling latency (i.e. white “blank” part). However, latencies are still significant on BOLT; we are investigating how to eliminate blank as much as possible.
Argobots and BOLT
We are contributing to the external projects Argobots and BOLT, both of which are used by many collaborators at domestic/foreign universities, research institutes, and private companies. The collaboration is one strength of this research; we can solve real problems by interacting with people who are using them in their workloads. Actually, now one of the students is studying at Argonne National Laboratory near Chicago as a long-term visiting student and working together with other Ph.D. students and postdocs from not only North America but also various European, Asian, and African countries. See Argobots (https://press3.mcs.anl.gov/argobots/) and BOLT (https://press3.mcs.anl.gov/bolt/) for details. If you are interested in this work (or the internship experience), please text me (iwasaki@eidos.ic.i.u-tokyo.ac.jp / siwasaki@anl.gov)